;){kind=link}
OpenAI全新发布o1模型 - 我们正式迈入了下一个时代。
大半夜的,OpenAI抽象了整整快半年的新模型。

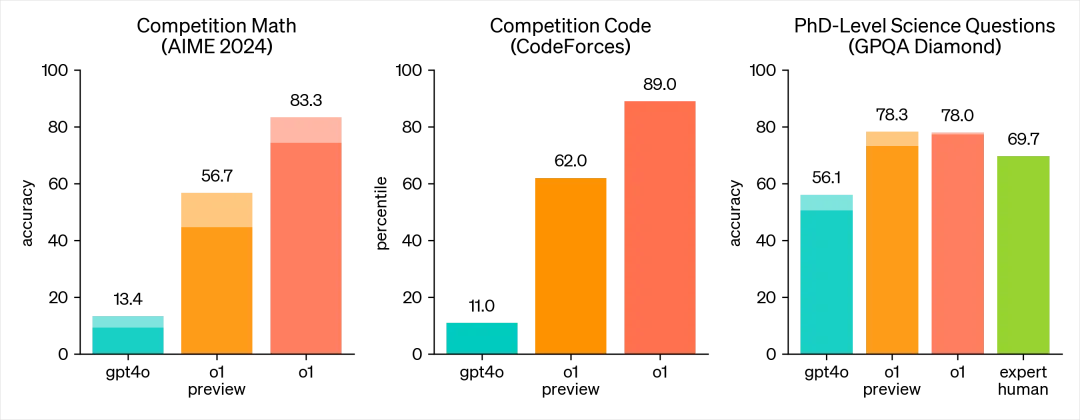
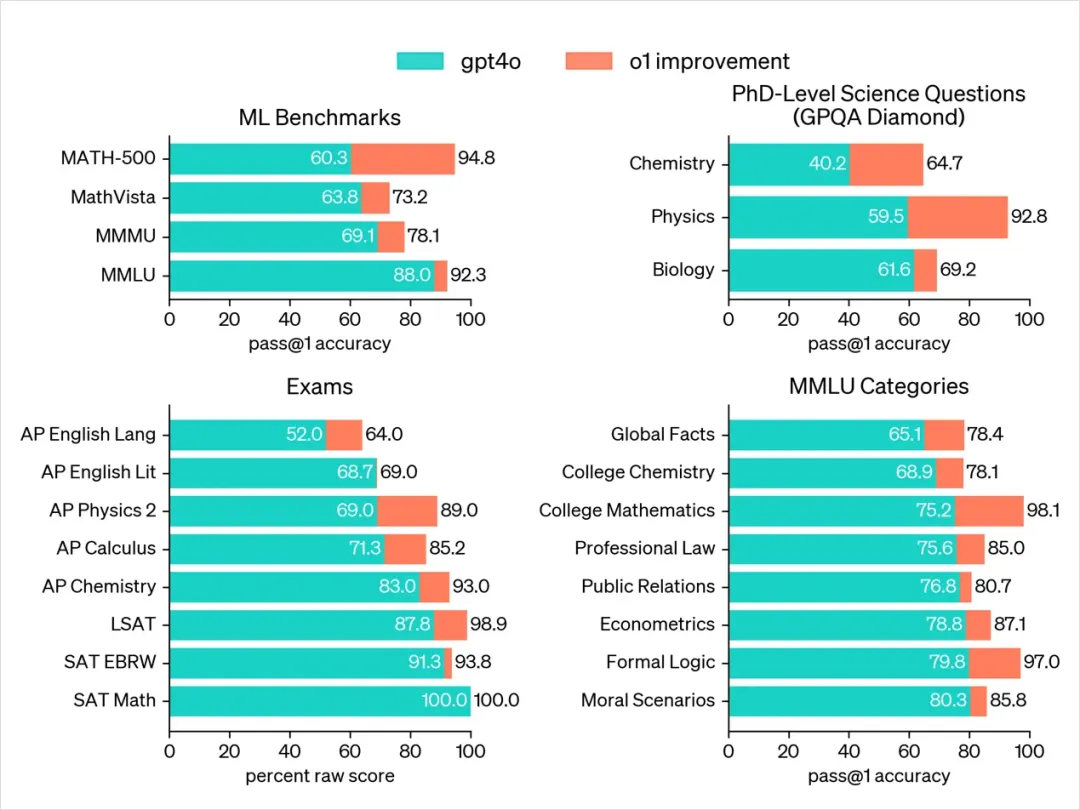
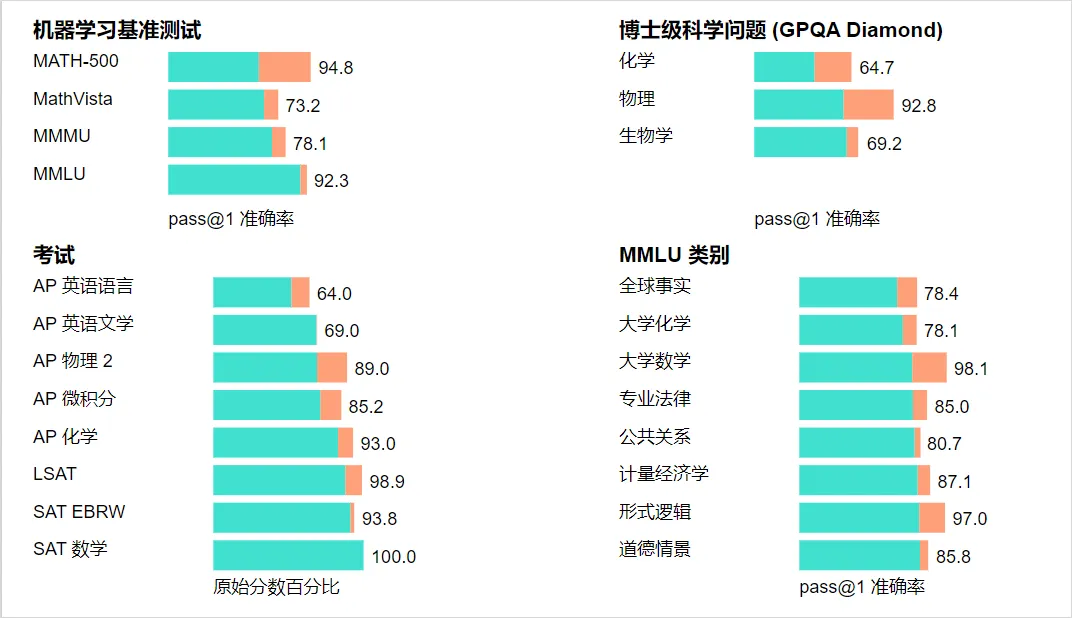
这就是所谓的全面超越,尤其在针对化学、物理和生物学专业知识的基准测试GPQA-diamond中,o1模型的表现完全超越了人类博士专家,成为有史以来第一个达到这一成就的模型。
o1之所以能取得如此卓越的成就,关键在于其采用了Self-play RL技术。对于不了解这一技术的读者,可以参考我之前的预测文章来深入了解。
通过Self-play RL,o1学会了如何锻炼其思维链条并完善所使用的策略。它具备了自我纠错的能力,能够将复杂的步骤分解为更简单的部分,并在当前方法失效时尝试不同的解决方案。这些能力正是我们人类最核心的思考方式——慢思考。
诺贝尔经济学奖得主丹尼尔·卡尼曼在其著作《思考,快与慢》中详细阐述了人类的两种思考方式。其中,快思考是快速、自动、直觉性的反应,而无需过多思考;而慢思考则需要我们付出努力,进行逻辑性的、有意识的思考。
现在,o1已经迈出了坚实的一步,拥有了人类慢思考的特质。在回答问题之前,它会进行反复的思考、拆解、理解和推理,然后给出最终的答案。这种增强的推理能力在处理科学、编程、数学等复杂问题时极具价值。
例如,o1可以被医疗研究人员用于注释细胞测序数据,被物理学家用于生成量子光学所需的复杂数学公式,以及被各领域的开发人员用于构建和执行多步骤工作流等。o1无疑是一个全新的数据驱动引擎,其未来的进化速度将令人震撼。
写到此处,我不禁感到有些沮丧。与一年后的o1相比,我可能真的变得微不足道了。目前,o1模型已经逐步向所有ChatGPT Plus和Team用户开放,未来也有可能会向免费用户开放。
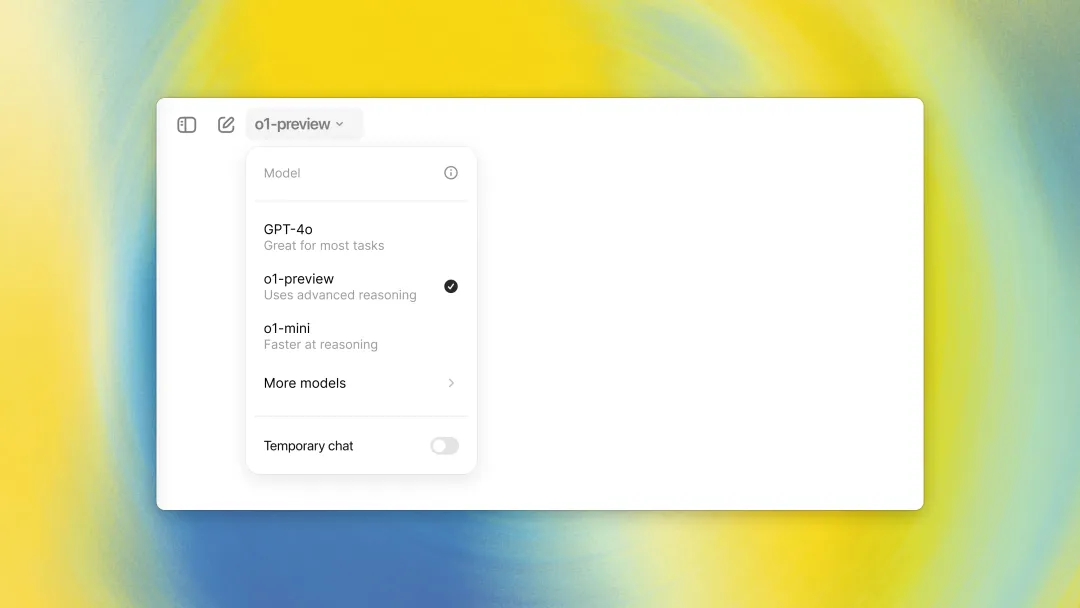
现在存在两个版本的模型:o1预览版和o1-mini。o1-mini以其更快的处理速度、更小的体积以及更亲民的价格脱颖而出,尤其在数学和代码推理方面表现出色。然而,它在世界知识方面相对欠缺,因此更适合那些需要推理能力但不需要广泛世界知识的应用场景。
在使用限制上,o1预览版每周提供30条对话机会,而o1-mini则更为慷慨,每周提供50条。值得注意的是,这里的限制不再是以前按小时计算,而是直接以周为单位,这也从侧面反映了o1模型的昂贵成本。
对于开发者而言,目前只有已经支付了1000美元、达到等级5的开发者才能使用这些模型,并且每分钟的使用次数被限制在20次以内。这些限制看起来都相当严格。
尽管在功能上有所阉割,但考虑到这是早期版本,我们仍然可以理解这些限制。



当然,我会立即尝试这个新的模型。
目前,这个模型似乎还不支持之前所有的功能,比如图片理解、图片生成、代码解释器以及网页搜索等,它现在只是一个可以进行对话的基础模型。
我首先向它提出了一个曾经非常棘手的问题:
“农夫需要将狼、羊和白菜都安全地带过河,但他每次只能带一样东西。而且,狼和羊不能单独留在河边,否则狼会吃掉羊;同样,羊和白菜也不能单独相处,否则羊会吃掉白菜。请问农夫应该如何安排,才能确保所有东西都安全过河?”

在6秒的思考后,o1给出了一个近乎完美的回答,展现出了其高效与准确性。
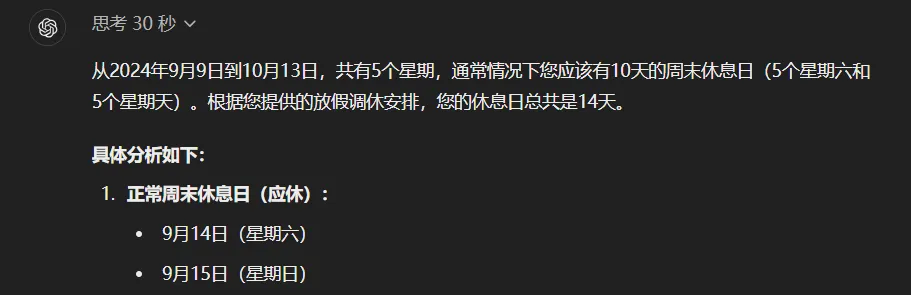
再提及之前曾困扰众多大模型的复杂调休问题,问题描述如下:
“这是2024年中国从9月9日(星期一)至10月13日的放假及调休安排:上6天班后休息3天,再上3天班休息2天,接着上5天班休息1天,然后上2天班休息7天,最后上5天班再休息1天。请问,在这个期间,我因为放假比原本应休的周末多休了几天?”
面对这一挑战,o1在深思熟虑了整整30秒后,给出了一个精确无误的答案,其准确度令人叹为观止,甚至精确到了每一天。



面对全新的挑战,我感到有些困惑。
在我个人尝试的过程中,我发现,针对以GPT为代表的快速思考大模型时代所形成的一些思考习惯,如逐步推理等,在o1模型上似乎已不再适用,甚至可能产生负面影响。
OpenAI给出的最佳实践建议是:
保持提示简洁明了:o1模型擅长理解和响应简短且清晰的指令,无需过多的指导或说明。
避免使用思路链提示:由于o1模型能够在内部进行推理,因此无需提示它“逐步思考”或“解释推理过程”。
使用分隔符提高清晰度:为了更清楚地指示输入的不同部分,可以使用三重引号、XML标签或章节标题等分隔符,帮助模型更好地理解和解释各部分内容。
限制检索增强生成中的附加上下文:在提供附加上下文或文档时,应仅包含最相关的信息,以避免模型响应过度复杂化。
此外,我想谈谈关于思考时长的问题。
目前o1模型的思考时间为一分钟,但如果是真正的通用人工智能(AGI),思考时间的延长可能会带来更为惊人的成果。
当AGI能够证明数学定理、研发癌症药物或进行天体研究时,每一次的思考都可能持续几小时、几天甚至几周。而最终的结果,可能会让所有人感到震惊和难以置信。
现在,我们无法想象未来的AI将会是一个怎样的存在。
在我看来,o1模型的未来远不止于成为一个普通的ChatGPT。它将成为我们迈向下一个时代最伟大的基石。
“我们通往AGI的路上,已经没有任何阻碍。”这句话,我现在毫不犹豫地坚信着。
星光璀璨的下一个时代,在今天,已经正式到来了。